DataTorrent RTS Configuration
This document covers all the information required to configure DataTorrent RTS to run with Hadoop 2.2+. Basic understanding of Hadoop 2.x, including HDFS and YARN is required. To learn more about Hadoop 2.x visit hadoop.apache.org.
Installation
If you have not installed DataTorrent RTS already, follow the installation instructions in the installation guide.
Configuration Files
System configuration is stored in local files on the machine where
the DT Gateway was installed, as well as Apache Apex DFS root directory
selected during the installation. The local file custom-env.sh can be used
to configure CLASSPATH, JAVA_HOME, and various runtime settings.
Depending on the installation type, these may be located under /opt/datatorrent/current/conf or ~/datatorrent/current/conf. See installation guide for details.
(install dir)/conf/custom-env.sh
This file can be used to configure behavior of DT Gateway service,
as well as apex command line utility. After adding custom properties
to this file, dtgateway and Apex CLI utilities need to be restarted for
changes to take effect.
Example custom-env.sh configuration:
# Increase DT Gateway memory to 2GB
DT_GATEWAY_HEAP_MEM=2048m
Environment variables available for configuration
- DT_GATEWAY_HEAP_MEM – Maximum heap size allocated to DT Gateway service. Default is 1024m.
- DT_GATEWAY_DEBUG – Set to 1 to enable additional debug information in the dtgateway.log
- DT_CLASSPATH – Classpath used to load additional jars or properties for Apex CLI and dtgateway
- DT_LOG_DIR – Directory for log files
- DT_RUN_DIR – Directory for process id and other temporary files created at run time
(user home)/.dt/dt-site.xml
This file is used to customize the DataTorrent platform and the behavior of applications. It can be particularly useful for changing Gateway application connection address, or configuring environment specific settings, such as specific machine names, IP addresses, or performance settings which may change from environment to environment.
Example of a single property configuration in dt-site.xml:
<configuration>
<property>
<name>dt.operator.MyCustomStore.host</name>
<value>192.168.2.35</value>
</property>
…
</configuration>
Gateway Configuration Properties
- dt.gateway.listenAddress - The address and port DT Gateway listens to. Defaults to 0.0.0.0:9090
- dt.gateway.autoPublishInterval - The interval in milliseconds DT Gateway should publish application information on the websocket channel. Default is 1000.
- dt.gateway.sslKeystorePath - Specifying of the SSL Key store path enables HTTPS on the DT Gateway (See the dtGateway Security document)
- dt.gateway.sslKeystorePassword - The password of the SSL key store (See the dtGateway Security document)
- dt.gateway.allowCrossOrigin - Setting it to true allows cross origin HTTP access to the DT Gateway. Default is false.
- dt.gateway.authentication.(OPTION) - Determines the scheme of Hadoop security authentication (See the dtGateway Security document).
- dt.gateway.http.authentication - Determines the scheme of DT Gateway HTTP security authentication (See the dtGateway Security document).
- dt.gateway.staticResourceDirectory - The document root directory where the DT Gateway should serve from for the /static HTTP path.
Application Configuration Properties
For a complete list of configurable application properties see the Attributes section below.
Resources Management and Performance Tuning
The platform provides continuous information about CPU, Memory, and Network usage for the system as a whole, individual running applications, operators, streams, and various internal components. These statistics are available via REST API, Apex CLI, and dtManage.
The platform is also responsible for
- Honoring the resource restrictions enforced by the YARN RM and taking preventive action to ensure they are met. This is done at both launch time (fit the execution plan to the number of containers and their sizes), as well as at run time.
- Honoring resource constraints an application developer may provide such as the amount of memory allocated to individual operators, associated buffer servers, or the number of partitions.
STRAM works with the YARN RM on a continual basis to ensure that resource constraints are met. As a multi-tenant application, it is crucial to be able to perform within given resource limits. The design of the platform enables effective management of all three types of resources (CPU, Memory, I/O).
CPU
CPU utilization is computed on a per-thread basis within a container by the StreamingContainer; this value is also, in effect, the per-operator value since each operator is a single threaded application. CPU utilization is also computed for the buffer-server as well as other common tasks within a container.
Network
Network usage management is needed to ensure that desired latency and throughput levels are achieved and any applicable SLA terms are met.
The platform provides real-time statistics on the number of bytes or tuples processed by each operator. Application developers can modulate network traffic using a couple of mechanisms: - Adjust the locality of streams: Using THREAD_LOCAL or CONTAINER_LOCAL can reduce network load substantially as discussed below. - Adjust the number of partitions and unifiers.
RAM
STRAM keeps track of resource usage on per container basis. Appropriate attributes can be set to limit the amount of RAM on a per-operator or per-container basis.
Spike Management
Streaming applications do not have the same throughput (events/second) for all 24 hours of the day; occasional spikes in the incoming data rate are common. Most streaming applications resolve this dichotomy by providing resources for the peak. So, resource utilization is suboptimal for most of the day because resources, though unused, are locked up and therefore unusable by other applications in a multi-tenant environment.
The platform provides mechanisms to manage the spikes by adding partitions during peak, and removing them once the spike subsides.
Partitioning
Partitioning is a core mechanism to distribute computation (and the associated resource utilization) across the cluster. It is discussed, along with the related concept of unifiers, in greater detail in Application development and Operator Development.
Stream Modes
The platform support 5 stream modes, namely THREAD_LOCAL (intra-thread), CONTAINER_LOCAL (intra process/jvm), NODE_LOCAL (intra node), RACK_LOCAL (same rack), and unspecified. While designing an application, the modes should be decided carefully. All stream-modes are hints to the STRAM, and hence could be ignored if resources are not available, and could be changed on a run-time basis. There are pros and cons of each.
- THREAD_LOCAL: All the operators of the ports on this stream share the same thread. Tuples are thus passed via the thread call stack. The performance is massive and go into 100s of millions of tuples/sec. Do note that if the operations are compute intensive, them THREAD_LOCAL may not perform better than CONTAINER_LOCAL. Thread call stack is extremely efficient in terms of I/O (there is no I/O here), but the same thread does both the upstream and downstream computation. A limitation is that all downstream operators on this stream must have only one input port connected. If the JVM process is lost, all the operators are lost, and will be restarted again in another container.
- CONTAINER_LOCAL: All the operators of the ports on this stream are in the same process. Each denotes a separate thread, and tuples are passed in memory via a connectionBuffer as the intra-process communication mechanism. This mode has very high throughput and can easily do more than million tuples/sec. However, since there is no bufferserver, features that it provides (spooling, persistence) are not available, so memory needs may grow. This mode relies on the downstream operators consuming tuples, on average, at least as fast as they are emitted by the upstream operator. As with the previous mode, if the JVM process is lost, all the operators are lost, and will be restarted again in another container.
- NODE_LOCAL: All operators on this stream are on the same node. Inter-process communication via the local loopback interface is used. This mode is also very fast, as data does not traverse the NIC but it has a buffer-server and so all the features that the buffer-server provides (spooling, persistence) are available. If one container dies, all the operators in that container will obviously need to be recreated and restarted, but other operators remain unaffected. However if a node dies then all of its containers and the operators hosted by them need to be restarted.
- RACK_LOCAL: All operators on this stream are in the same rack. Communication is not as fast as the previous modes since data needs to pass through the NIC. Like the previous mode, it has a buffer-server and so all the features that buffer-server provides are available. Use of this mode reduces the probability of multi-operator outage since multiple operators are not constrained to run on the same node. This mode however will be affected by outage of a switch.
- Unspecified: This is the default mode and STRAM makes no special effort to achieve any particular locality. There are thus no guarantees on whether a stream will cross rack, node, or process boundaries.
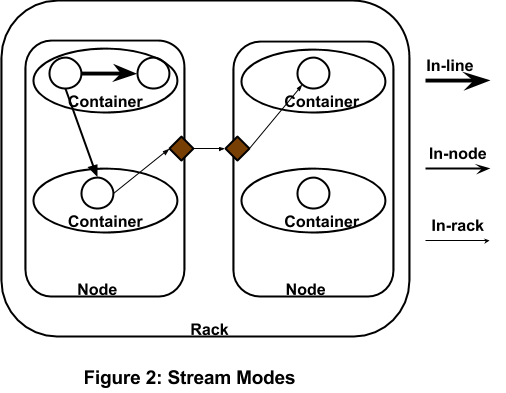
Multi-Tenancy and Security
The platform is a YARN native application, and so all security features
available in Hadoop also apply for securing Apache Apex applications.
The default security for the streaming application is Kerberos based.
Kerberos Authentication
Kerberos is a ticket based authentication system that provides authentication in a distributed environment where authentication between multiple users, hosts and services is needed. It is the de-facto authentication mechanism supported in Hadoop. To use Kerberos authentication, the Hadoop installation must first be configured for secure mode with Kerberos. Please refer to the administration guide of your Hadoop distribution on how to do that. Once Hadoop is running with Kerberos security enabled, DataTorrent platform also needs to be configured for Kerberos. There are two parts of the platform that need to be configured, CLI (Command Line Interface) and DT Gateway.
CLI Configuration
The DataTorrent command line interface is used to launch applications along with performing various other operations on applications. The security configuration for the CLI program is described in the Apache Apex security document available here.
DT Gateway Configuration
DT Gateway is a service that provides the backend functionality for the DataTorrent UI console. In a Hadoop cluster with Kerberos security enabled additional configuration is needed for this service to communicate with Hadoop. This is described in Gateway Security.
Console Authentication
Access to the UI console can be secured by having users authenticate before they can access the contents of the console. Different authentication mechanisms are supported including local password, Kerberos and LDAP. Please refer to Gateway Security for details of how to configure this.
Run-Time Management
Unlike Map-Reduce, streaming applications never end. They are designed to run 24x7, processing a continuous stream of input data. This makes run-time management of the applications very critical. The platform provides strong support for various operations. These include
- Runtime metrics and stats on various components of the application including aggregated metrics
- Ability to change the logical plan, physical plan, and execution plan of the application
- Ability to dump the current state of the application to enable re-launch (in case of Hadoop grid outage)
- Integration of STRAM state with Zookeeper (in later versions)
- Debugger, charting, and other tools triggered at run time
Dynamic Functional Modifications
Platform supports changes to an application at multiple stages.
Application design parameters (attributes and properties) can be
changed at launch time via the job configuration file and during runtime via
the apex tool or using the REST webservice calls. Support for runtime
changes is critical for operability as it enables changes to a running
application without being forced to kill it. This is a critical need for
streaming applications and a significant difference from map-reduce/batch
applications.
From an operational perspective, the platform will allow changes in both the logical plan (query modification, or properties modifications) and the physical plan (attribute modification generally and partitioning changes specifically).
Examples of dynamic changes to logical plan include - Changing properties of an operator - Adding or deleting a sub-dag. Some examples are - Change in persistence - Insertion of charts, debugger etc. - Query insertion on a particular stream
Any change to a logical plan will change the physical and the execution plan. Examples of dynamic changes only to physical plan include
- Change in attributes that triggers STRAM to change the number of physical operators.
- Runtime changes in load or grid resources (via RM, or outages), that triggers STRAM to change the physical plan to meet SLA, latency, resources usage goals
- Direct request to change the number of partitions of an operator. For example new input adapters to handle expected uptick in ingestion rate
Any change to a physical plan will change the execution plan. Examples of dynamic changes only to the execution plan include
- Changes in attributes that need a new execution plan
- Changes to stream modes
- Node recovery from an outage
Runtime Code
STRAM is able to reuse and move any code that is supplied with the initial launch of the application. The default behavior is for the jar to include all the library templates in addition to the application code. This enables STRAM to make changes to the application as the code is already available.
Load
STRAM manages runtime changes to ensure that the application scales up and down. This includes changes in load, changes in skew, changes in resource behavior (network goes slow) etc. STRAM proactively monitors the application and will make run time changes as needed.
Uptime
Node recovery is a change in the execution plan caused by external events (node outage) or RM taking resources back (preemption). The platform enables node recovery in three modes, namely, at least once, at most once, and exactly once. SLA enforcement in terms of latency, uptime, etc. is done via runtime changes.
Attributes
Attribute specification is the process by which operational customization is achieved. Currently, modification of attributes on an application that is already running is not supported. We intend to add this in future versions on an attribute by attribute basis. Attributes are parameters that the platform recognizes and acts on and are not part of user code. Attributes are the mechanism by which platform features can be customized. They are specified with a key and a value. In this section we list the attributes, their default values, and briefly explain what they do.
There are three kinds of attributes
- Application attributes
- Operator attributes
- Port attributes
For implementation details look at the javadocs. Some very common attributes are
- Application: Application window, Application name, Checkpoint window, Container JVM options, container memory, containers, max count, heartbeat interval, STRAM memory, launch mode, tuple recording, etc. See Context.DAGContext
- Operators: Initial partitions, checkpoint window, locality host, locality rack, memory, recovery attempts, stateless, storage agent, etc. See Context.OperatorContext
- Ports: Queue capacity, auto_record, partition parallel, etc. See Context.PortContext
These attributes are available via the Context class and can be
accessed in the setup call of an operator.
Application Configuration
Starting from RTS release 2.0.0, applications are configured through Application Packages. Please refer to the Application Packages for details.
Adjusting Logging Levels
Application Logging
Logging levels for specific classes or groups of classes can be raised or
lowered at runtime from dtManage application view with the
Set Log Levels button. Explicit class paths or patterns like
org.apache.hadoop.* or com.datatorrent.* can be used to adjust logging to
valid log4j levels such as DEBUG or INFO. This produces immediate change in
the logs, but does not persist across application restarts.
For permanent changes to logging levels, lines similar to these can be inserted
into dt-site.xml. To specify multiple patterns, use a comma-separated list.
<property>
<name>dt.loggers.level</name>
<value>com.datatorrent.*:DEBUG,org.apache.*:INFO</value>
</property>
Full DEBUG logging can be enabled by adding these lines:
<property>
<name>dt.attr.DEBUG</name>
<value>true</value>
</property>
Custom log4j Properties for Application Packages
There are two ways of setting custom log4j properties in an Apex application
package
-
At the Application level. This will ensure that the custom log4j properties are used for all containers including Application Master. An example:
<property> <name>dt.attr.CONTAINER_JVM_OPTIONS</name> <value>-Dlog4j.configuration=custom_log4j.properties</value> </property> -
At an individual operator level. This sets the custom log4j properties only on the container that is hosting the operator. An example:
<property> <name>dt.operator.<OPERATOR_NAME>.attr.JVM_OPTIONS</name> <value> -Dlog4j.configuration=custom_log4j.properties</value> </property>
Make sure that the file custom_log4j.properties is part of your application
jar and is located under src/main/resources. Some examples of custom log4j
properties files follow.
-
Writing to a file
log4j.rootLogger=${hadoop.root.logger} // this is set to INFO / DEBUG, RFA log4j.appender.RFA=org.apache.log4j.RollingFileAppender log4j.appender.RFA.layout=org.apache.log4j.PatternLayout log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} [%t] %-5p %c{2} %M - %m%n log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file} -
Writing to Console
log4j.rootLogger=${hadoop.root.logger} // this is set to INFO / DEBUG, RFA log4j.appender.RFA=org.apache.log4j.ConsoleAppender log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} [%t] %-5p %c{2} %M - %m%n log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
dtGateway Logging
DT Gateway log level can be changed to DEBUG by settings following environment variable before launching DT Gateway (as of version 2.0).
export DT_GATEWAY_DEBUG=1
Hadoop Tuning
YARN vmem-pmem ratio tuning
After performing a new installation, sometimes the following message is displayed while launching an application:
Application application_1408120377110_0002 failed 2
times due to AM Container for appattempt_1408120377110_0002_000002
exited with exitCode: 143 due to:
Container\[pid=27163,containerID=container_1408120377110_0002_02_000001\]
is running beyond virtual memory limits. Current usage: 308.1 MB of 1 GB
physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing
container.
Dump of the process-tree for container_1408120377110_0002_02_000001 :
PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
27208 27163 27163 27163 (java) 604 19 2557546496 78566
/usr/java/default/bin/java
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n -Xmx768m
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/dt-heap-2.bin
-Dhadoop.root.logger=DEBUG,RFA
-Dhadoop.log.dir=/disk2/phd/dn/yarn/userlogs/application_1408120377110_0002/container_1408120377110_0002_02_000001
To fix this yarn.nodemanager.vmem-pmem-ratio in yarn-site.xml should be
increased from 2 to 5 or higher. Here is an example setting:
<property>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers. Container allocations are
expressed in terms of physical memory, and virtual memory usage
is allowed to exceed this allocation by this ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>10</value>
</property>