Kafka to HDFS Sync Application
Summary
Ingest messages from kafka to hadoop HDFS for continuous ingestion to hadoop. The source code is available at: https://github.com/DataTorrent/app-templates/tree/master/kafka-to-hdfs-sync.
Please send feedback or feature requests to: feedback@datatorrent.com
This document has a step-by-step guide to configure, customize, and launch this application.
Steps to launch application
-
Click on the AppHub tab from the top navigation bar.

-
Page listing the applications available on AppHub is displayed. Search for Kafka to see all applications related to Kafka.
 Click on import button for
Click on import button for Kafka to HDFS Sync App. -
Notification is displayed on the top right corner after application package is successfully imported.

-
Click on the link in the notification which navigates to the page for this application package.
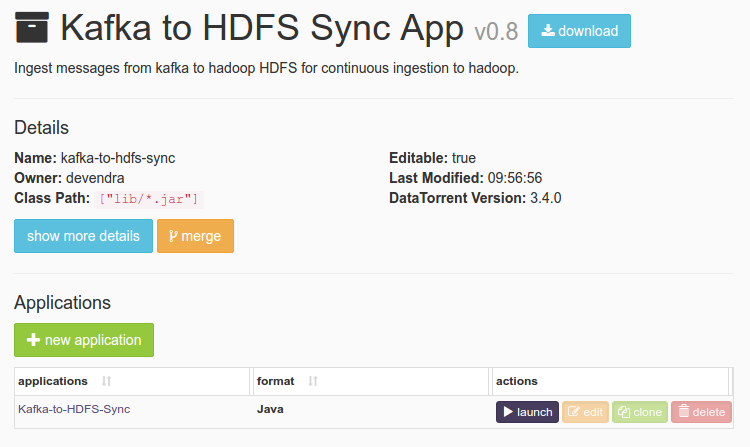 Detailed information about the application package like version, last modified time, and short description is available on this page. Click on launch button for
Detailed information about the application package like version, last modified time, and short description is available on this page. Click on launch button for Kafka-to-HDFS-Syncapplication. -
Launch Kafka-to-HDFS-Syncdialogue is displayed. One can configure name of this instance of the application from this dialogue.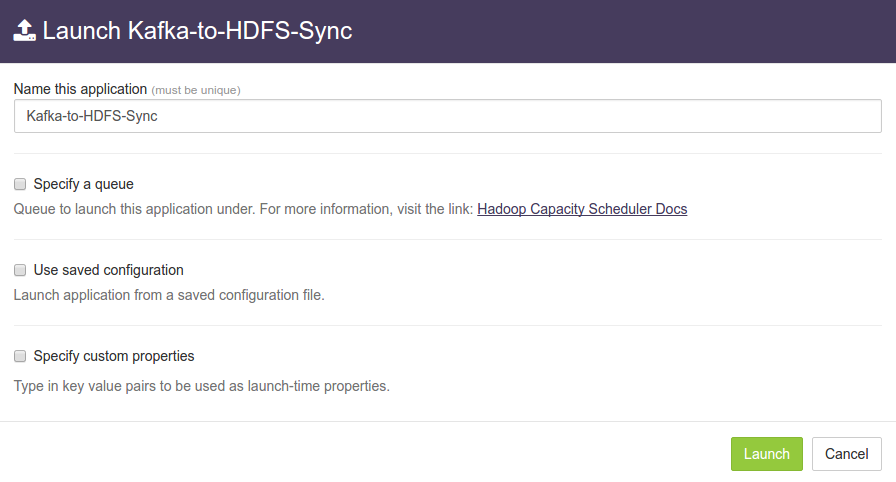
-
Select
Use saved configurationoption. This displays list of pre-saved configurations. Please selectsandbox-memory-conf.xmlorcluster-memory-conf.xmldepending on whether your environment is the DataTorrent sandbox, or other cluster.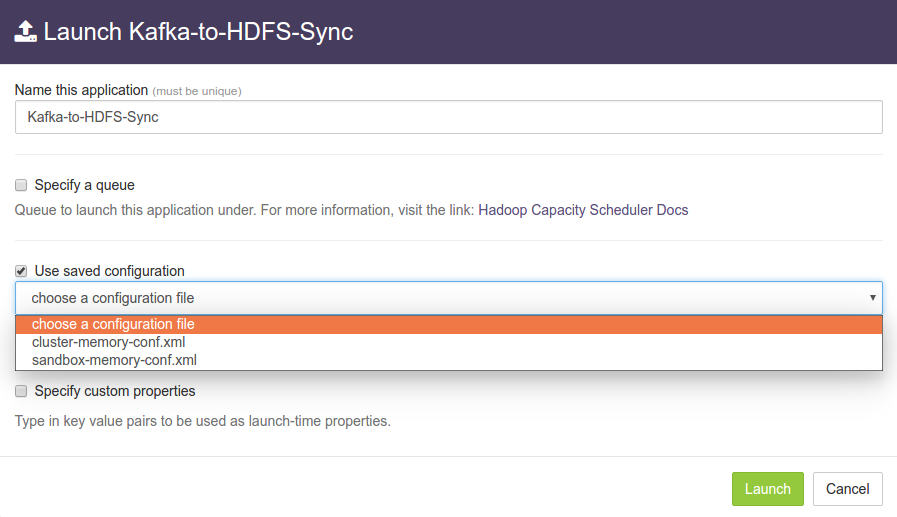
-
Select
Specify custom propertiesoption. Click onadd default propertiesbutton.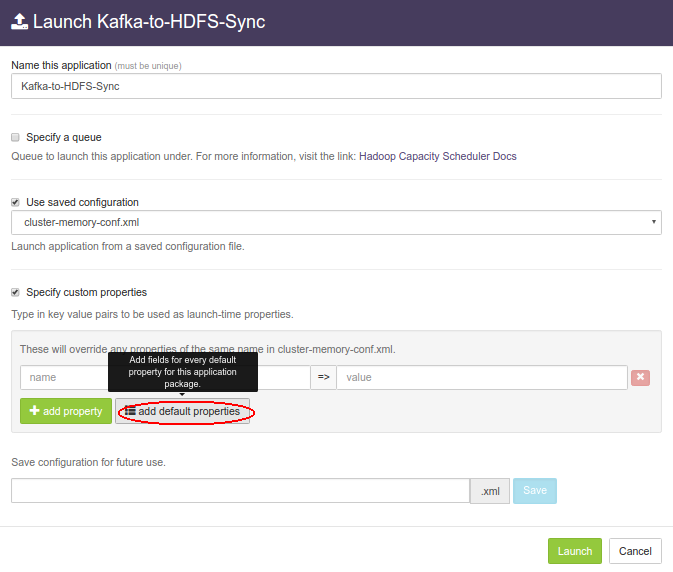
-
This expands a key-value editor pre-populated with mandatory properties for this application. Change values as needed.
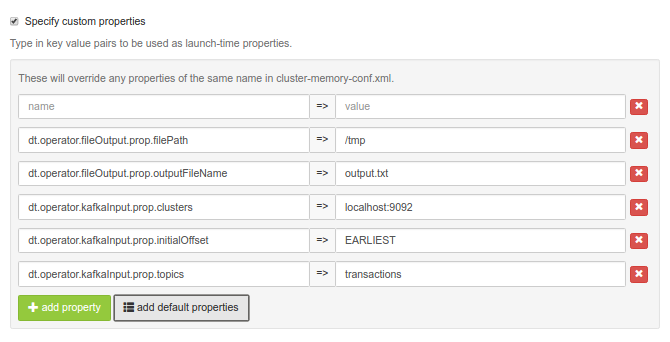 For example, suppose we wish to process all messages from topic
For example, suppose we wish to process all messages from topic transactionsat the kafka server running on localhost port 9092 and write them tooutput.txtunder/user/appuser/outputon HDFS. Properties should be set as follows:name value dt.operator.fileOutput.prop.filePath /user/appuser/output dt.operator.fileOutput.prop.outputFileName output.txt dt.operator.kafkaInput.prop.clusters localhost:9092 dt.operator.kafkaInput.prop.initialOffset EARLIEST dt.operator.kafkaInput.prop.topics transactions Details about configuration options are available in Configuration options section.
-
Click on the
Launchbutton on lower right corner of the dialog to launch the application. A notification is displayed on the top right corner after application is launched successfully and includes the Application ID which can be used to monitor this instance and find its logs.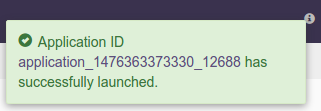
-
Click on the
Monitortab from the top navigation bar.
-
A page listing all running applications is displayed. Search for current application based on name or application id or any other relevant field. Click on the application name or id to navigate to application instance details page.

-
Application instance details page shows key metrics for monitoring the application status.
logicaltab shows application DAG, Stram events, operator status based on logical operators, stream status, and a chart with key metrics.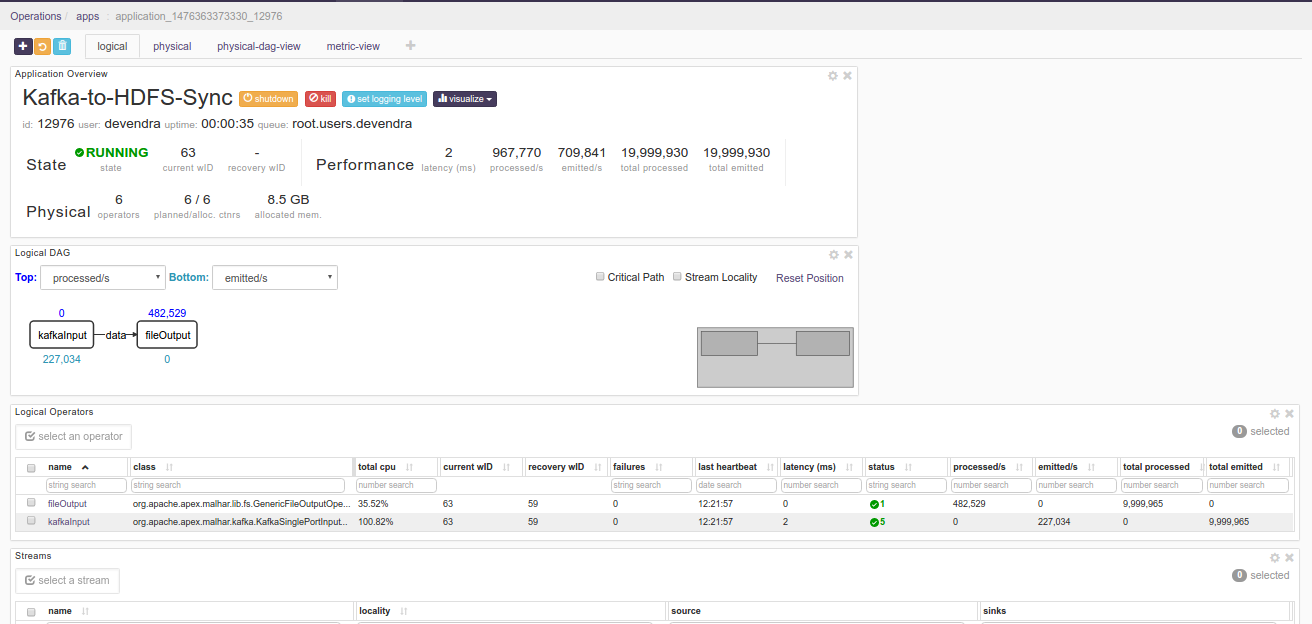
-
Click on the
physicaltab to look at the status of physical instances of the operator, containers etc.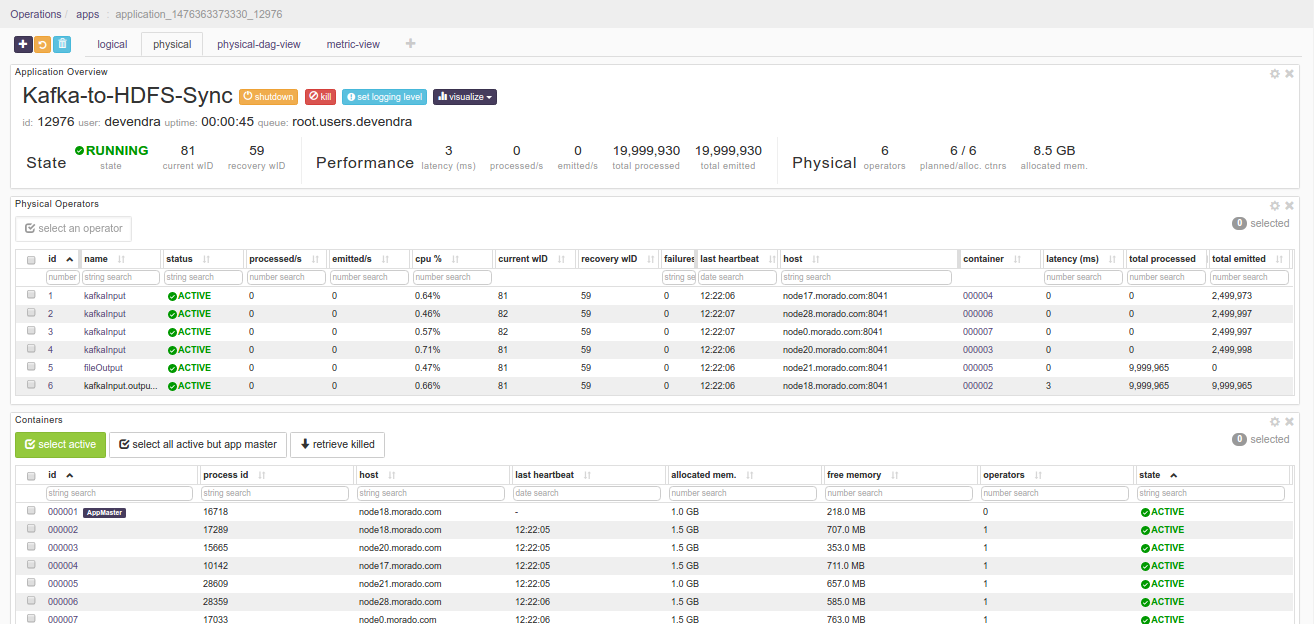
Configuration options
Mandatory properties
End user must specify the values for these properties.
| Property | Description | Type | Example |
|---|---|---|---|
| dt.operator.fileOutput.prop.filePath | Output path for HDFS | String | /user/appuser/output |
| dt.operator.fileOutput.prop.outputFileName | Output file name | String | output.txt |
| dt.operator.kafkaInput.prop.clusters | Comma separated list of kafka-brokers | String | node1.company.com:9098, node2.company.com:9098, node3.company.com:9098 |
| dt.operator.kafkaInput.prop.initialOffset | Initial offset to read from Kafka | String |
|
| dt.operator.kafkaInput.prop.topics | Topics to read from Kafka | String | event_data |
Advanced properties
There are pre-saved configurations based on the application environment. Recommended settings for datatorrent sandbox edition are in sandbox-memory-conf.xml and for a cluster environment in cluster-memory-conf.xml.
| Property | Description | Type | Default for cluster- memory - conf.xml |
Default for sandbox- memory -conf.xml |
|---|---|---|---|---|
| dt.operator.fileOutput.prop.maxLength | Maximum length for output file after which file is rotated | long | Long.MAX_VALUE | Long.MAX_VALUE |
You can override default values for advanced properties by specifying custom values for these properties in the step specify custom property step mentioned in steps to launch an application.
Steps to customize the application
-
Make sure you have following utilities installed on your machine and available on
PATHin environment variables -
Use following command to clone the examples repository:
git clone git@github.com:DataTorrent/app-templates.git -
Change directory to 'examples/tutorials/kafka-to-hdfs-sync':
cd examples/tutorials/kafka-to-hdfs-sync -
Import this maven project in your favorite IDE (e.g. eclipse).
-
Change the source code as per your requirements. Some tips are given as commented blocks in the Application.java for this project
-
Make respective changes in the test case and
properties.xmlbased on your environment. -
Compile this project using maven:
mvn clean packageThis will generate the application package with
.apaextension in thetargetdirectory. -
Go to DataTorrent UI Management console on web browser. Click on the
Developtab from the top navigation bar.
-
Click on
upload packagebutton and upload the generated.apafile.
-
Application package page is shown with the listing of all packages. Click on the
Launchbutton for the uploaded application package.
Follow the steps for launching an application.